一、准备工作
1、环境配置
[root@bogon ~]# yum -y remove java-1.8.0-openjdk-headless.x86_64 #卸载yum方式安装的jdk
[root@bogon ~]# yum install -y java #安装jdk
[root@bogon ~]# java -version #验证
[root@bogon ~]# yum -y install wget
[root@bogon ~]# yum -y install vim
2、调整防火墙
systemctl stop firewalld
# 或者采用以下方式
firewall-cmd --zone=public --add-port=5601/tcp --permanent #防火墙添加5601端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent #防火墙添加9200端口
二、部署ELK
1、安装Elasticsearch
获取安装文件到 /usr/local/
[root@bogon ~]# cd /usr/local #切换到非root目录
[root@bogon local]# wget https://mirrors.huaweicloud.com/elasticsearch/7.8.0/elasticsearch-7.8.0-linux-aarch64.tar.gz
[root@bogon local]# tar -zxvf elasticsearch-7.8.0-linux-aarch64.tar.gz #解压
修改文件 /usr/local/elasticsearch-7.8.0/config/elasticsearch.yml,取消注释以下内容所在行
- cluster.name: elk-Cluster #ELK的集群名称,名称相同即属于是同一个集群
- node.name: elk-node1 #本机在集群内的节点名称
- path.data: /elk/data #数据存放目录
- path.logs: /elk/logs #日志保存目录
- network.host:192.168.1.199 #本机IP地址
- http.port:9200 #端口
- cluster.initial_master_nodes: [“elk-node1”] #节点名称
创建用户以及用户组
[root@bogon local]# groupadd es_group #新建用户组
[root@bogon local]# useradd -g es_group es_user #向组内添加用户
[root@bogon local]# chown -R es_user:es_group elasticsearch-7.8.0 #授权
[root@bogon local]# ll #查看文件夹授权是否成功
创建数据和日志文件夹并授权
[root@bogon local]# mkdir -p /elk/{data,logs} #创建
[root@bogon local]# chown es_user:es_group /elk/ -R
[root@bogon local]# chmod 777 -R /elk #使elasticsearch对 elk 文件夹有读写权限
以非root用户身份运行elasticsearch
[root@bogon local]# su es_user #切换用户
[es_user@bogon local]# ./elasticsearch-7.8.0/bin/elasticsearch #运行
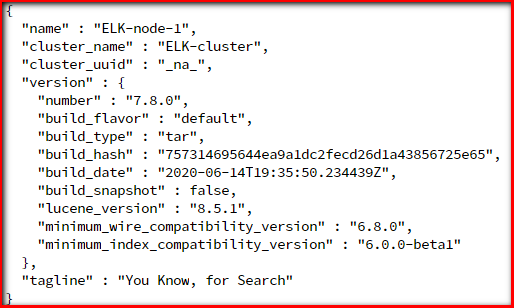
验证elasticsearch是否配置正确
- 在浏览器访问:http://192.168.1.199:9200/
- 或在终端输入命令:
curl 192.168.1.199:9200
监控elasticsearch集群状态:
http://192.168.1.199:9200/_cluster/health?pretty=true
- 如果status为green,表示在正常运行
- 如果status为yellow,表示副本分片丢失
- 如果status为red,表示主分片丢失
常见问题
#问题1:
ERROR: [2] bootstrap checks failed[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least[65536]
#解决方案:
编辑 /etc/security/limits.conf,追加以下内容;
[root@bogon local]# vi /etc/security/limits.conf //添加, 【注销后并重新登录生效】
* soft nofile 655350
* hard nofile 655360
* soft nproc 1024
* hard nproc 2048
####################################解释####################################
# soft nproc :单个用户可用的最大进程数量(超过会警告);
# hard nproc :单个用户可用的最大进程数量(超过会报错);
# soft nofile:可打开的文件描述符的最大数(超过会警告);
# hard nofile:可打开的文件描述符的最大数(超过会报错);
############################################################################
此文件修改后需要重新登录用户,才会生效
#问题2:
ERROR:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
#解决方案:
编辑 /etc/sysctl.conf,追加以下内容:
[root@bogon local]# vi /etc/sysctl.conf
############################################################################
vm.max_map_count=655360
############################################################################
保存后,执行:
sysctl -p
2、安装logstash
获取安装文件:
[root@bogon ~]# cd /usr/local
[root@bogon local]# wget https://mirrors.huaweicloud.com/logstash/7.8.0/logstash-7.8.0.tar.gz
[root@bogon local]# tar -zxvf logstash-7.8.0.tar.gz #解压
aarch64-linux/文件夹下缺少platform.conf文件,在ARM架构的服务器上运行时会导致代码异常报错,所以我们需要增加paltform.conf文件,并重新打包jar文件
[root@bogon ~]# cd /usr/local/logstash-7.8.0/logstash-core/lib/jars
[root@bogon jars]# mkdir jruby-complete-9.2.11.1
[root@bogon jars]# cp jruby-complete-9.2.11.1.jar jruby-complete-9.2.11.1/
[root@bogon jars]# mv jruby-complete-9.2.11.1.jar jruby-complete-9.2.11.1.jar.bak
[root@bogon jars]# unzip -d jruby-complete-9.2.11.1/ jruby-complete-9.2.11.1/jruby-complete-9.2.11.1.jar
[root@bogon jars]# rm -f jruby-complete-9.2.11.1/jruby-complete-9.2.11.1.jar
[root@bogon jars]# cp jruby-complete-9.2.11.1/META-INF/jruby.home/lib/ruby/stdlib/ffi/platform/aarch64-linux/types.conf jruby-complete-9.2.11.1/META-INF/jruby.home/lib/ruby/stdlib/ffi/platform/aarch64-linux/platform.conf
[root@bogon jruby-complete-9.2.11.1]# cd jruby-complete-9.2.11.1
[root@bogon jruby-complete-9.2.11.1]# zip -r jruby-complete-9.2.11.1.jar *
[root@bogon jruby-complete-9.2.11.1]# mv jruby-complete-9.2.11.1.jar ../
[root@bogon jruby-complete-9.2.11.1]# cd ../
[root@bogon jars]# rm -rf jruby-complete-9.2.11.1
运行测试
- 测试标准输出
[root@bogon jars]# cd /usr/local
[root@bogon local]# ./logstash-7.8.0/bin/logstash -e 'input { stdin {} } output { stdout { codec => rubydebug} }'
hello world #输入
{
"@version" => "1", #事件版本号,一个事件就是一个ruby对象
"@timestamp" => 2020-08-21T04:30:35.106Z, #当前事件发生的事件
"host" => "linux-elk1.exmaple.com", #标记事件发生在哪里
"message" => "hello world" #消息的具体内容
}
新建配置文件,读取指定日志文件,发送到elasticsearch
[root@bogon local]# vim /etc/logs/system-log.conf
input {
file {
path => "/var/log/messages" #日志路径
type => "systemlog" #类型,自定义,在进行多个日志收集存储时可以通过该项进行判断输出
start_position => "beginning" #logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,类似 less +F 的形式运行。
stat_interval => "2" #logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒
}
}
output {
elasticsearch {
hosts => ["192.168.1.199:9200"] #elasticsearch服务器地址
index => "logstash-%{type}-%{+YYYY.MM.dd}" #索引名称
}
}
指定文件启动logstash
[root@bogon local]# ./logstash-7.8.0/bin/logstash -f /etc/logs/system-log.conf
3、安装kibana
获取安装文件
[root@bogon ~]# cd /usr/local
[root@bogon local]# wget https://mirrors.huaweicloud.com/kibana/7.8.0/kibana-7.8.0-linux-x86_64.tar.gz
[root@bogon local]# tar -zxvf kibana-7.8.0-linux-x86_64.tar.gz #解压
由于在ARM架构服务器上运行,所以需要将 /usr/local/kibana-7.8.0-linux-x86_64/ 下的node文件夹替换为ARM版本的
[root@bogon local]# cd kibana-7.8.0
[root@bogon kibana-7.8.0]# mv node node.bak
[root@bogon kibana-7.8.0]# wget https://mirrors.huaweicloud.com/nodejs/v10.21.0/node-v10.21.0-linux-arm64.tar.gz
[root@bogon kibana-7.8.0]# mv node-v10.21.0-linux-arm64 node
修改文件 /usr/local/kibana-7.8.0-linux-x86_64/config/kibana.yml.yml,取消注释以下内容所在行
server.host: "192.168.1.199" #监听端口
server.port: 5601 #监听地址
elasticsearch.hosts: ["http://192.168.1.199:9200"] #elasticsearch服务器地址
i18n.locale: "zh-CN" #修改为中文
授权
[root@bogon kibana-7.8.0]# cd ../
[root@bogon local]# chown -R es_user:es_group kibana-7.8.0-linux-x86_64
以非root用户身份运行kibana
[root@bogon local]# su es_user #切换用户
[es_user@bogon local]# ./kibana-7.8.0-linux-x86_64/bin/kibana #运行
访问 http://192.168.1.199:5601 ,查看效果
4、通过logstash收集系统message日志
- 在 /usr/local/logstash-7.8.0/config 下创建随意名称的 logstash 配置文件 example.conf
- 需要注意的问题是:通过logstash收集别的日志文件,前提需要logstash用户对被收集的日志文件有读的权限并对要写入的文件有写的权限
- 特别需要注意的是,索引名称不能出现大写符号,不然会报错
[root@bogon local]# vim /usr/local/logstash-7.8.0/config/example.conf
input {
file {
path => "/var/log/messages" #日志路径
type => "systemlog" #类型,自定义,在进行多个日志收集存储时可以通过该项进行判断输出
start_position => "beginning" #logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,类似 less +F 的形式运行。
stat_interval => "1" #logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒
}
}
output {
elasticsearch {
hosts => ["192.168.1.199:9200"] #elasticsearch服务器地址
index => "example-%{type}-%{+YYYY.MM.dd}" #索引名称
}
}
检测配置文件是否有语法错误
[root@bogon local]# logstash -f /usr/local/logstash-7.8.0/config/example.conf -t
修改日志文件的权限
[root@bogon local]# chmod 777 /var/log/messages
重启logstash
[root@bogon local]# logstash -f /usr/local/logstash-7.8.0/config/example.conf
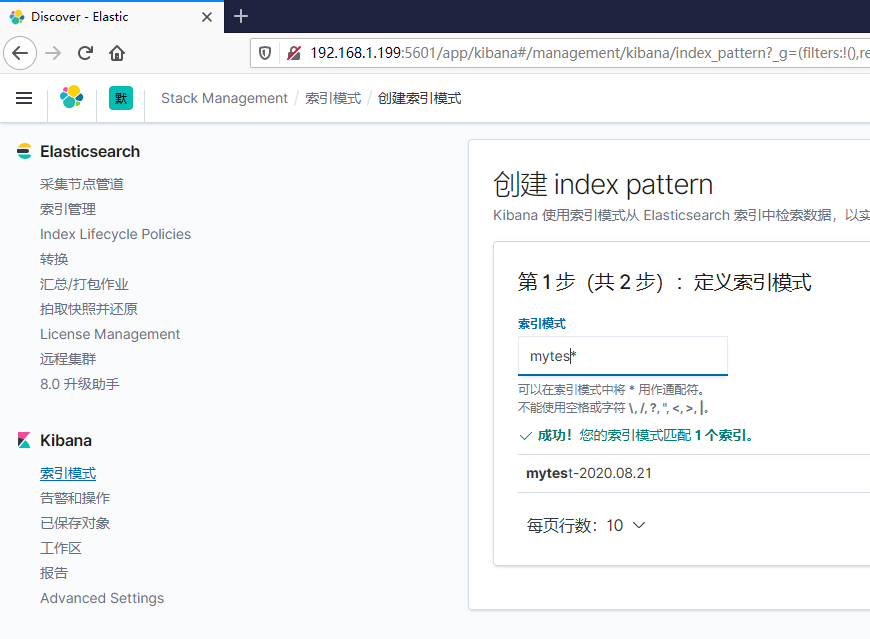
访问 http://192.168.1.199:5601 ,定义索引模式,查看数据
原创文章,作者:witersen,如若转载,请注明出处:https://www.witersen.com
 微信扫一扫
微信扫一扫